AI / Machine Learning
StaySure
Hotel Booking Cancellation Predictor
F1 Score
0.85
on the held-out test set
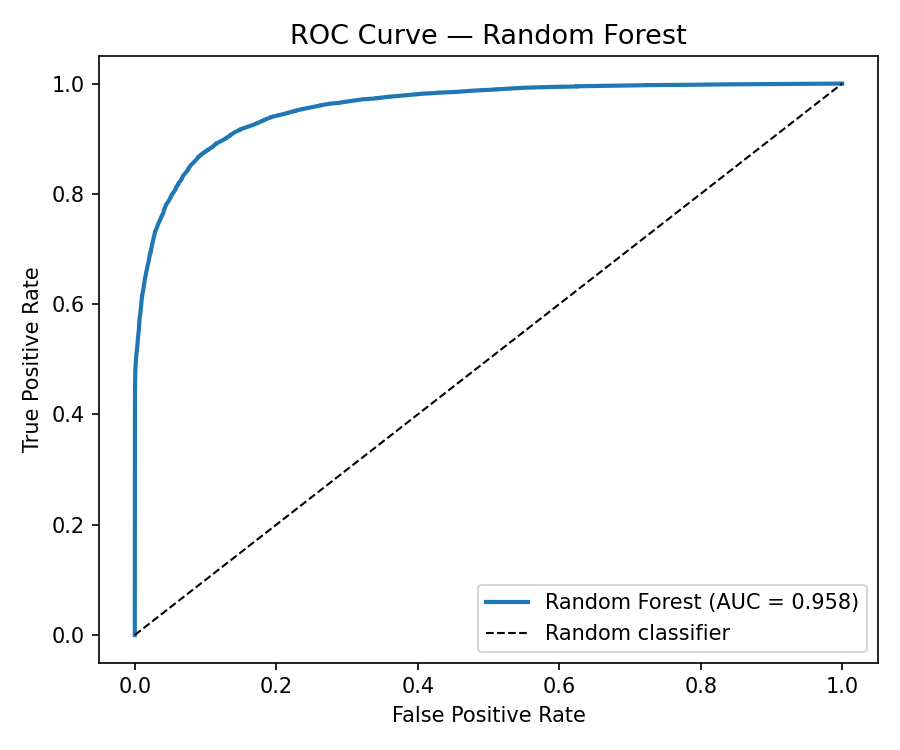
ROC-AUC
0.958
strong class separation
Training data
119,390
real bookings
Problem
Hotel booking cancellations cost the hospitality industry billions annually. If a hotel could predict —
at booking time — which reservations are likely to cancel, they could adjust pricing, overbooking policies,
and staffing accordingly.
Solution
An end-to-end ML project trained on 119,390 real hotel bookings. Given details like lead time,
deposit type, booking channel, and previous cancellations, the model predicts whether a booking
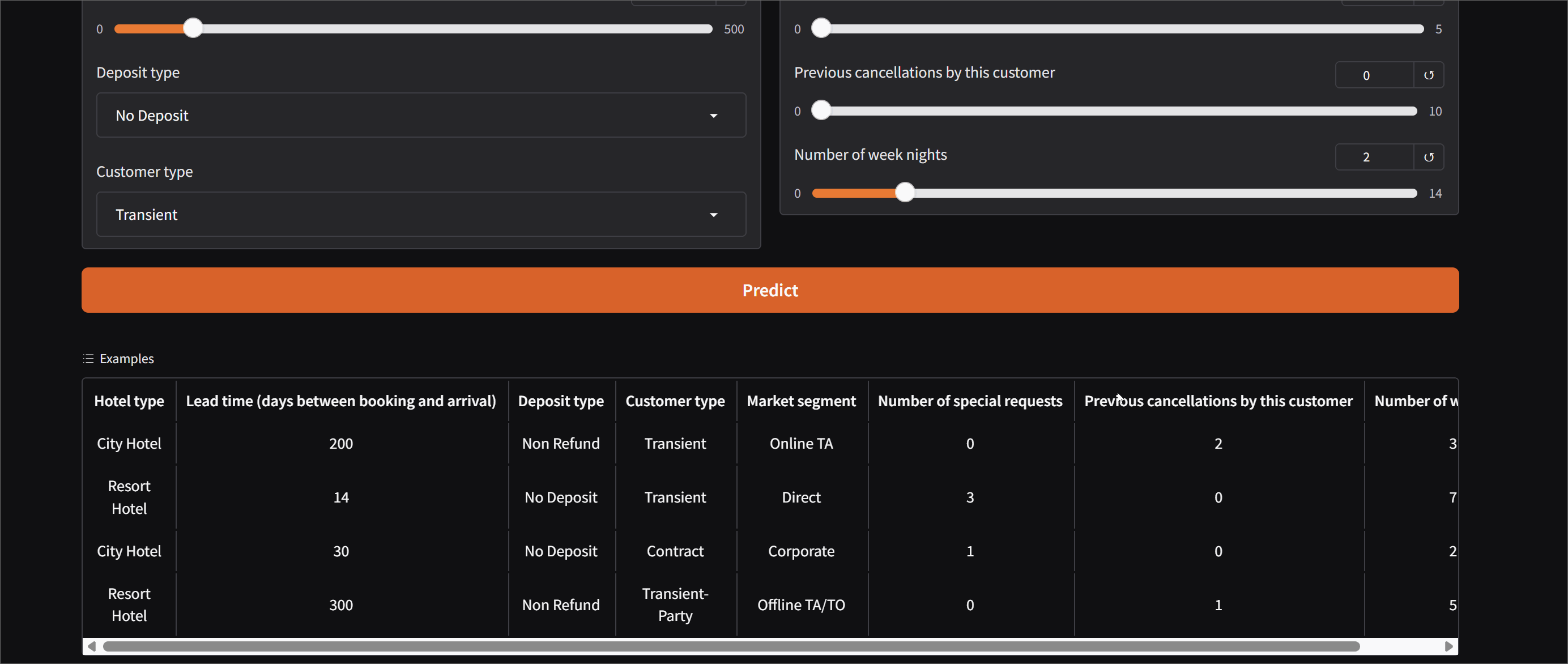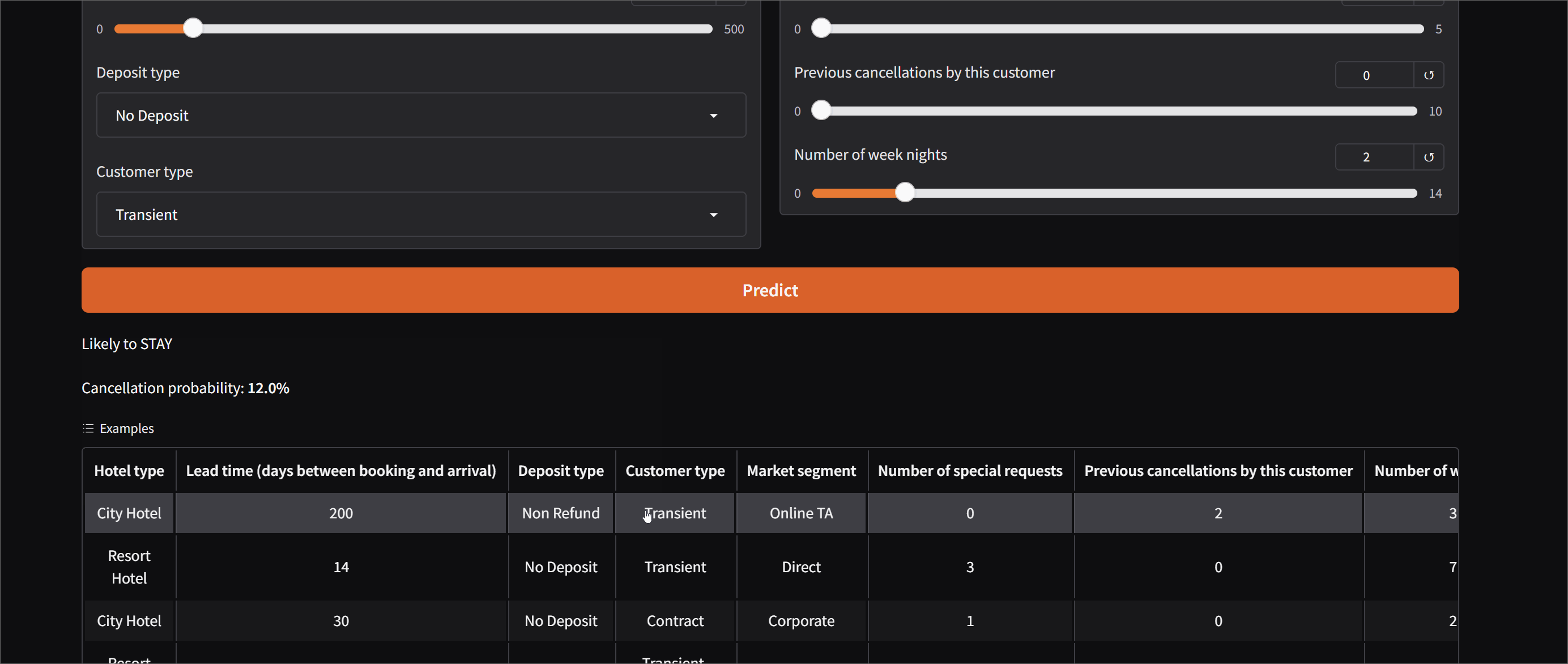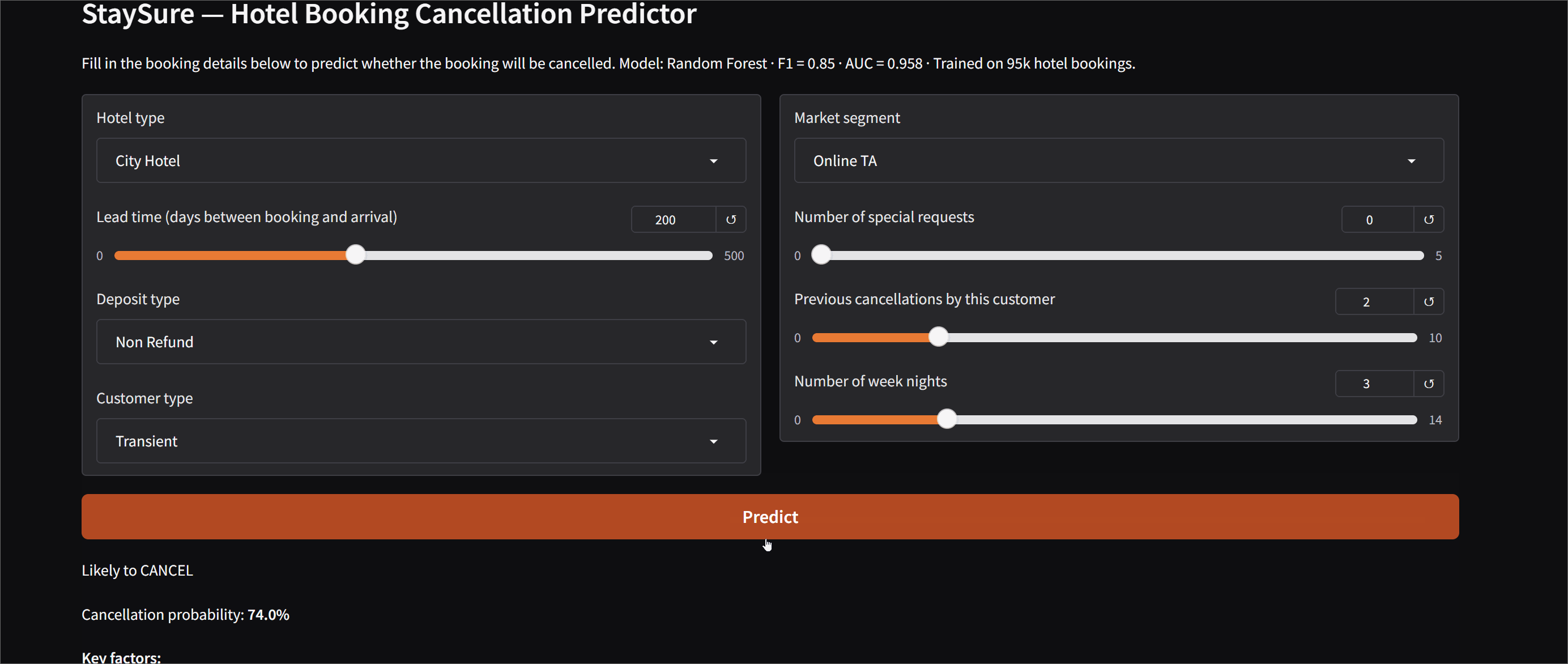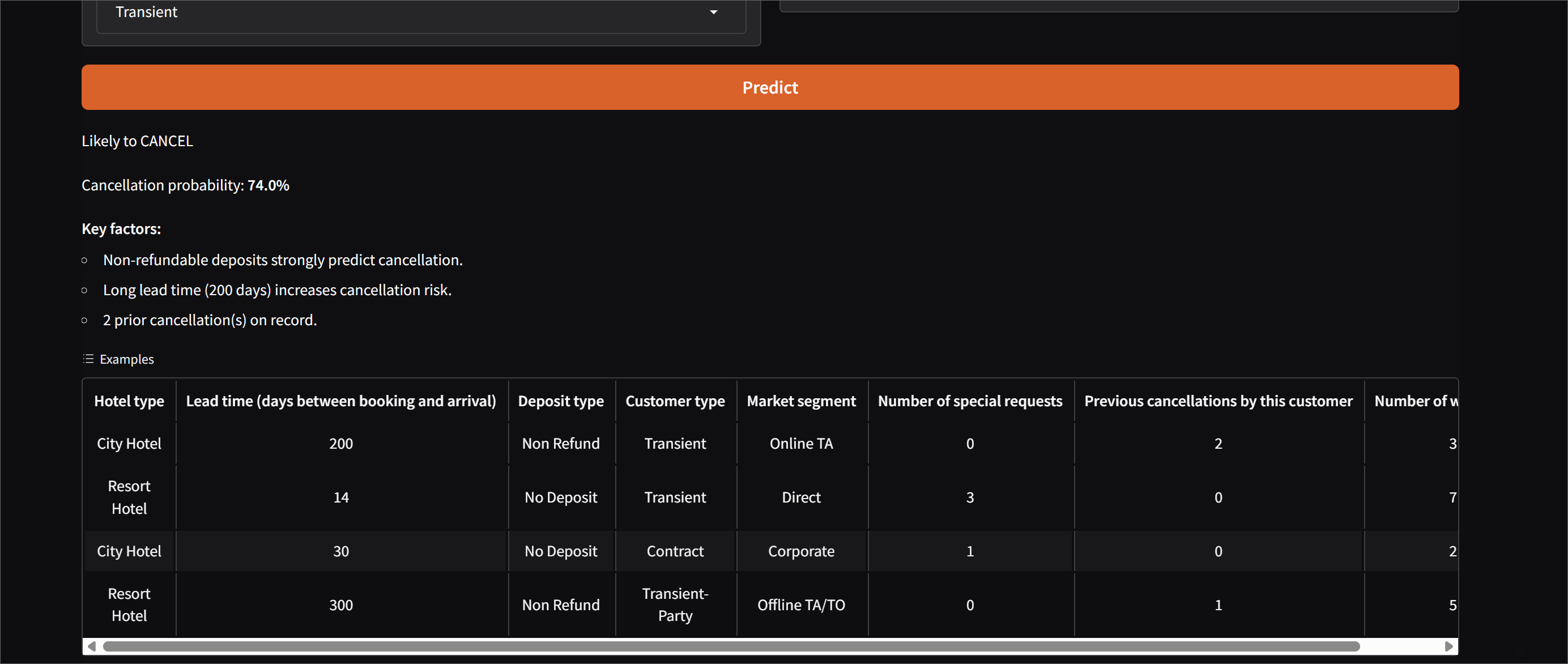
will be cancelled — and explains why using SHAP feature importance values. Deployed as an
interactive Gradio demo on Hugging Face Spaces.
Tech stack
| EDA | Jupyter · pandas · seaborn |
| Modeling | scikit-learn Pipelines · LogisticRegression · RandomForest · XGBoost |
| Hyperparameter tuning | GridSearchCV (3-fold) |
| Experiment tracking | MLflow (local file backend) |
| Explainability | SHAP summary + per-prediction force plots |
| Deployment | Gradio on Hugging Face Spaces |
ML pipeline
Raw CSV (119,390 rows)
│
▼
EDA notebook
│ leakage check, target distribution, correlations
▼
sklearn Pipeline (ColumnTransformer)
│ impute nulls → encode categoricals → scale numerics
▼
Model comparison (LR baseline → RF → XGBoost)
│ GridSearchCV, logged to MLflow
▼
Best model (Random Forest) → test set evaluation
│ confusion matrix, ROC-AUC, F1
▼
SHAP analysis → feature importance
│
▼
Gradio app → Hugging Face Spaces (public demo)Model results
| Model | F1 Score | ROC-AUC |
|---|---|---|
| Logistic Regression (baseline) | 0.74 | 0.86 |
| Random Forest (winner) | 0.85 | 0.958 |
| XGBoost | 0.83 | 0.95 |
Random Forest narrowly edged XGBoost on F1; chosen for its faster inference and simpler dependency surface for the Hugging Face deployment.
Confusion matrix
ROC curve
Selected lessons
- EDA leakage hunt comes first. Several columns in the dataset (e.g.
reservation_status) effectively encode the target — using them inflates accuracy to 100%. Removing them is the difference between a "model" and a lookup table. - Class imbalance ≠ broken metrics. ~37% cancellation rate is mild but not balanced. F1 over accuracy as the primary metric — a 63%-accurate model that always predicts "not cancelled" is useless.
- Pipelines > manual preprocessing. sklearn
ColumnTransformer+Pipelineguarantees test-set transformations match the training-set transformations. A whole class of "works in notebook, fails in production" bugs disappears. - SHAP explanations are the deploy unlock. Showing why a booking is flagged turns "the AI says no" into a tool a hotel manager would actually trust.
Local setup
git clone https://github.com/neuralxjam/staysure
cd staysure
uv sync
jupyter lab notebooks/01_eda.ipynb # start with EDA