Data Engineering
CryptoPulse
Crypto Market ETL Pipeline + Dashboard
Problem
Crypto price data is public and fast-moving, but raw API responses are messy and unnormalised.
Most people look at a chart and see a number — a data engineer sees a pipeline problem:
how do you reliably ingest, clean, transform, and serve that data so it's always fresh and queryable?
Solution
A fully automated data pipeline that runs every 6 hours with zero manual steps:
- Ingest — Python fetches top-100 coin prices from CoinGecko's free API (no key required), validates each row with a pydantic model, writes a timestamped Parquet snapshot.
- Store — An idempotent loader appends the snapshot into DuckDB; duplicate timestamps are silently ignored via
INSERT OR IGNOREon a composite primary key. - Transform — dbt rebuilds a staging view and two mart tables (daily returns leaderboard, top gainers/losers), then runs 10 data-quality tests.
- Commit back — GitHub Actions commits the updated DuckDB file to the repo with
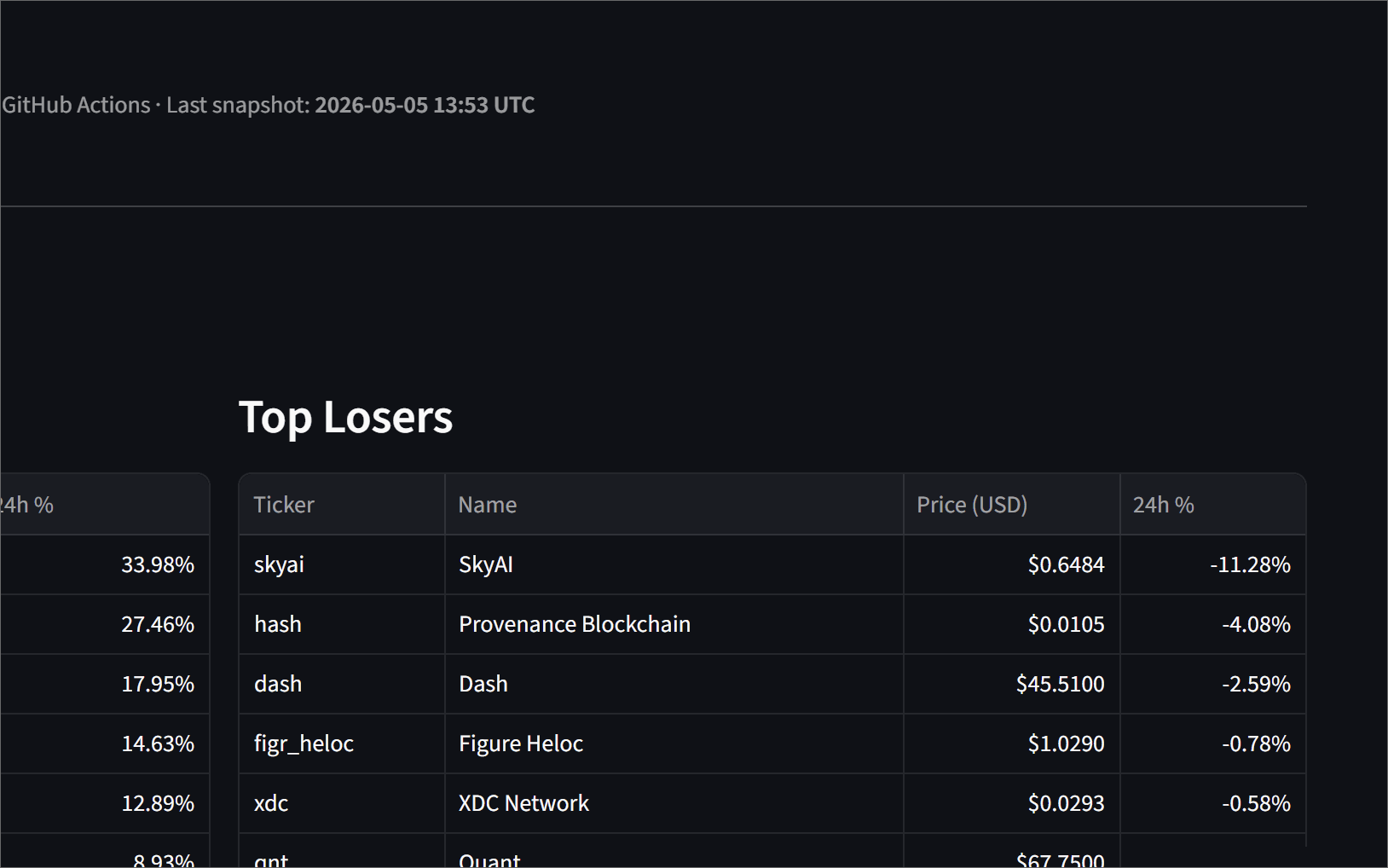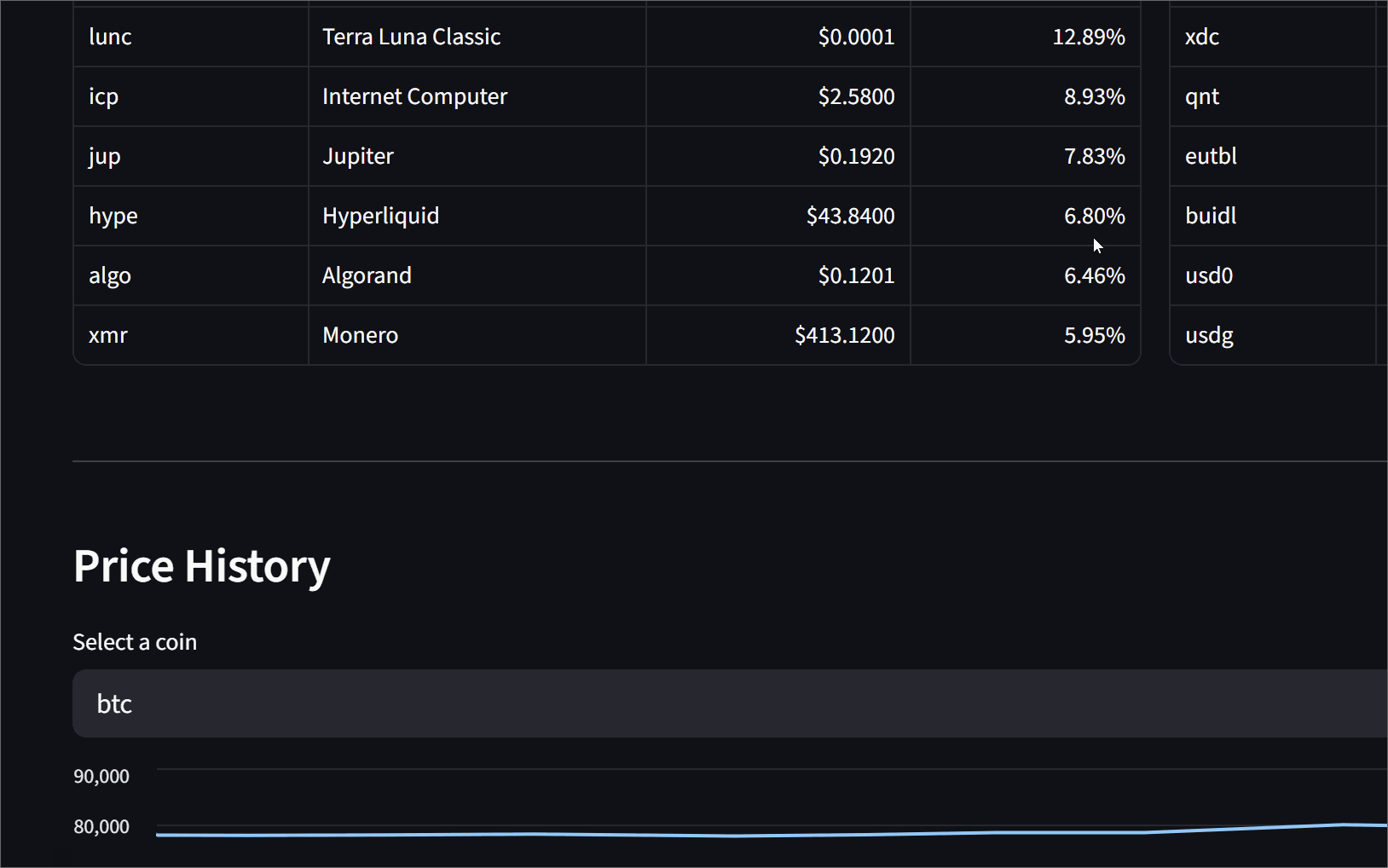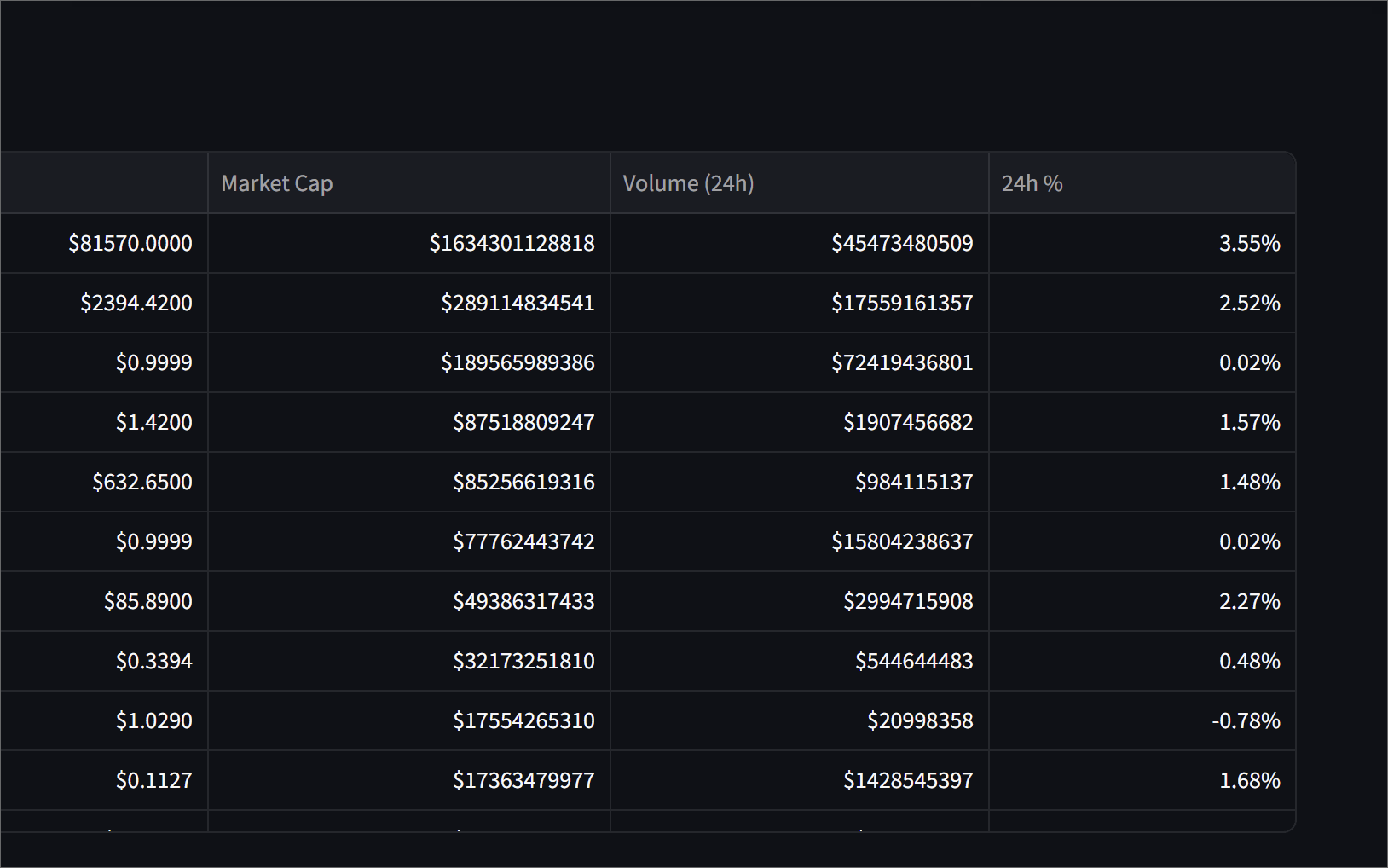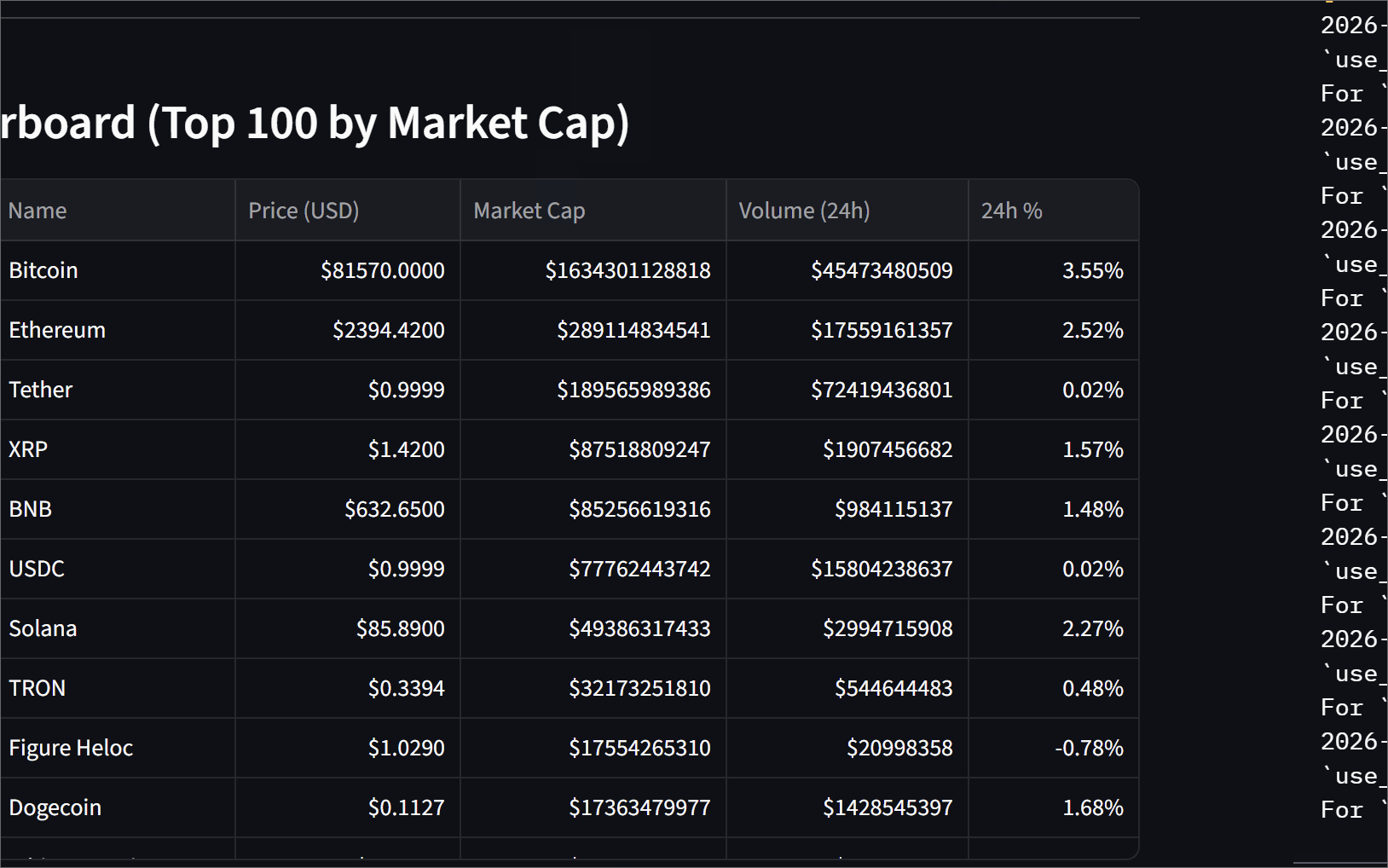
[skip ci]so the next cron run picks up fresh historical data. - Serve — A Streamlit dashboard reads from the mart tables and shows a movers section, a coin price history chart, and a full top-100 leaderboard.
Tech stack
| Ingestion | Python · httpx · pydantic |
| Storage | DuckDB (file-based, committed to repo) |
| Transformation | dbt-duckdb (staging → marts pattern) |
| Orchestration | GitHub Actions schedule: cron (every 6h) |
| Dashboard | Streamlit on Streamlit Community Cloud |
| Tests | dbt unique · not_null · accepted_values |
| Docs | dbt docs site hosted on GitHub Pages |
Architecture
GitHub Actions (cron 0 */6 * * *)
│
├─ ingest.py ──► data/raw/prices_<UTC>.parquet
│ │
├─ load.py ──────────────► cryptopulse.duckdb
│ │
│ ┌────────────────────┤ raw_prices (table)
│ │ │
├─ dbt run ────┤ stg_prices (view)
│ │ │
│ ├── mart_daily_returns (table)
│ └── mart_top_movers (table)
│
└─ git commit ──► pushes cryptopulse.duckdb back [skip ci]
Streamlit app reads marts → live public dashboardSelected lessons
- dbt staging → marts pattern — separating raw-to-clean from clean-to-business-logic means one place to fix schema changes, not every downstream model.
- Idempotency by design —
INSERT OR IGNOREon(id, ingested_at)makes the loader safe to re-run; the same lesson applies to every ETL job. - Jinja in SQL comments is parsed —
{{ ref(...) }}inside a comment creates a real dbt dependency and a false cycle error; always use plain text in comments. git pull --rebaseneeds a clean tree. In CI: commit first, then rebase on the remote, then push. Not the other way around.- Windows zoneinfo — Python's
zoneinfomodule needs thetzdataPyPI package on Windows (Linux gets it from the OS); catching this early saved a broken GitHub Actions run.